
在现实世界中,知识不仅以传统数据库中的结构化数据的形式出现,还以诸如书籍、研究论文、新闻文章、WEB页面及电子邮件等各种各样的形式出现。面对以这些形式出现的、浩如烟海的信息源,人类的阅读能力、时间精力等等往往不够,需要借助计算机的智能处理技术来帮助人类及时、方便的获取这些数据源中隐藏的有用信息。文本挖掘技术就在这种背景下产生和发展起来的。
文本挖掘的根本价值在于能把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本。使计算机能够通过对这种模型的计算和操作来实现对文本的识别。文本挖掘广泛应用于舆情监测、有害信息过滤、电子邮件和文献分析以及情感分析等领域。
今天我们来聊一聊如何用KNIME构造一个情感分析模型,以便后期对相似的文本进行情感分析。
下图是整个分析过程的概况:
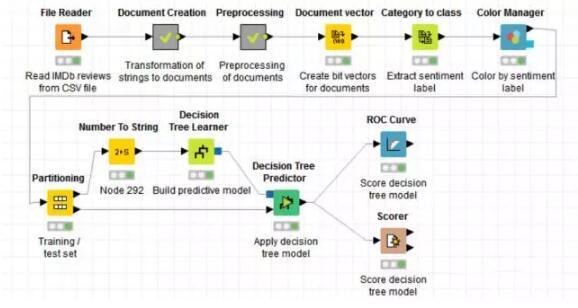
首先,我们从IMDb网站上获取关于《Girlfight》这部影片的2000条评论,储存为.CSV格式的文件,利用File Reader这个节点把文本读入。

现在我们要将文件中的字符串转化成文档,把文件中除了文档的列都过滤掉。
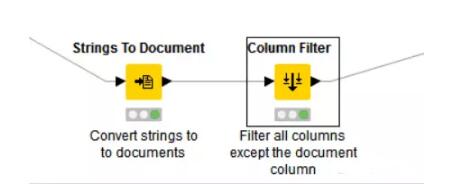
(上图即为Document Creation元节点里面的内容)
接着我们对这个文档进行文本的预处理。先后将标点清除,数字过滤掉,将小于三个词语的文档过滤掉,停用词过滤,将大写转化为小写,最后提取词干。

(上图即为Preprocessing元节点里面的内容)
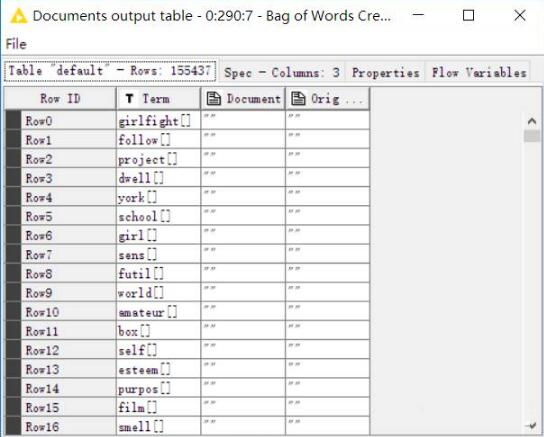
之后我们就可以创建词袋了,即把提取出来的词干扔进一个袋子里,可以看到,在本例中,我们创造的词袋中一共包含155437行数据。
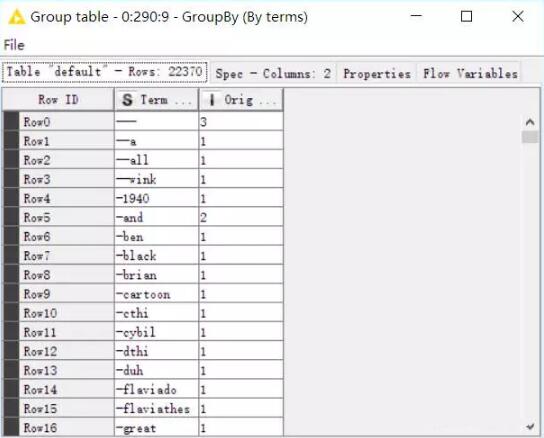
然后把词袋中的词转化为字符串,并根据原评论中词出现的次数分组,可以看到,分组后我们的词袋变成了22370行(这是因为之前的词是有重复的)。
之后我们过滤掉出现次数小于N的词,(注意这个N是由从原文件中提取出的行数经过一段语法计算决定的,在本例中,是用行数除以100)。
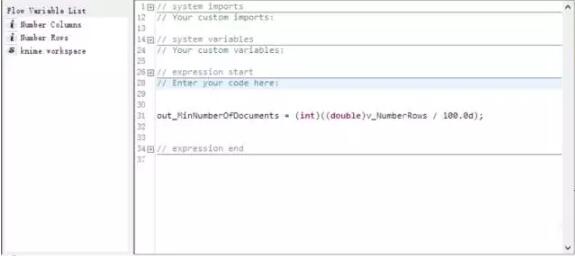
接着,我们以上一步过滤掉的词为参考,在最初创建的词袋中过滤掉它们,过滤后我们可用的词是100728行数据,最后计算这些词的词频。
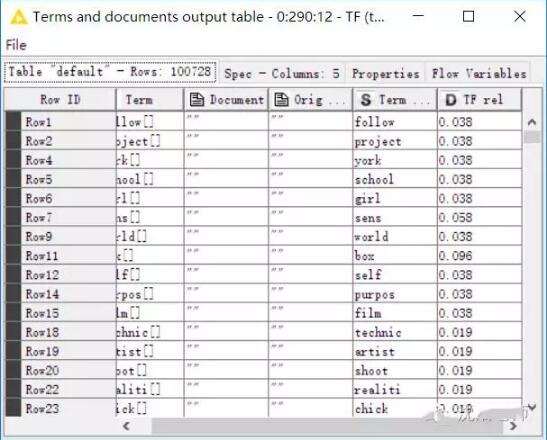
终于我们完成了文本的预处理过程。
现在,我们要为原始的评论创建向量,来观察词袋中的词是否存在于原文本中。之后提取原评论的情感标签,并以颜色分类。
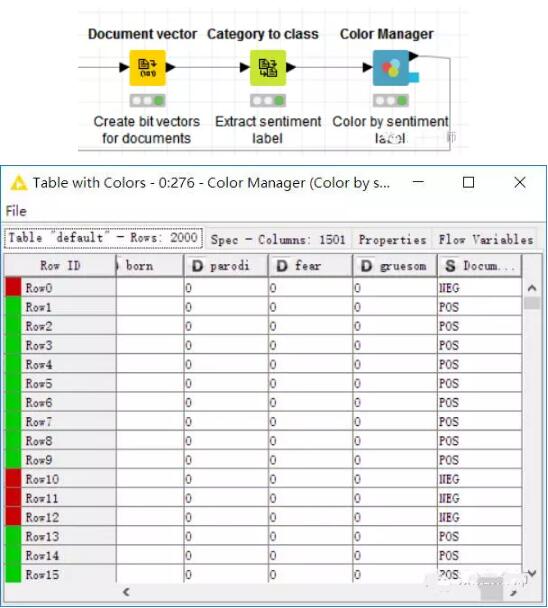
接着我们把2000条评论分成两个部分,本例中将70%用作训练集,来构建决策树模型,另外的30%用来测试决策树模型。
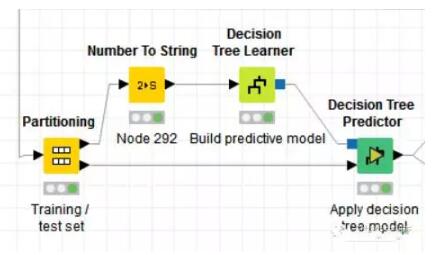
这就是决策树模型,根据一个词是否存在将文本集分为两个部分。
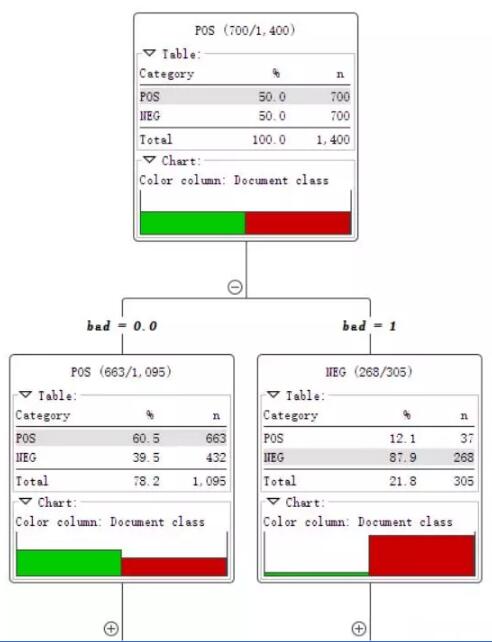
直到所有记录都属于同一类决策树就会停止。
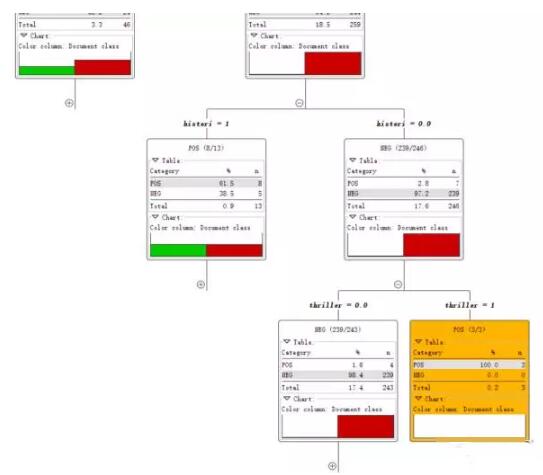
最后我们用两种方法来对模型进行评价。
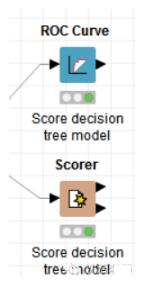
一种是ROC曲线,曲线下方面积达到0.9397,如此可见,模型还是很不错的。
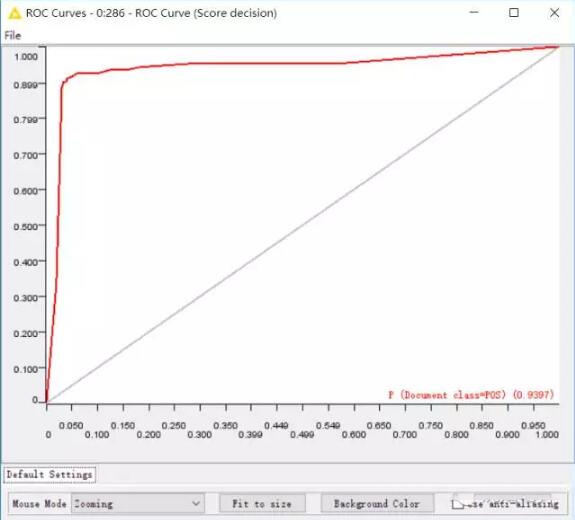
再来看一下矩阵,准确率高达93.167%。
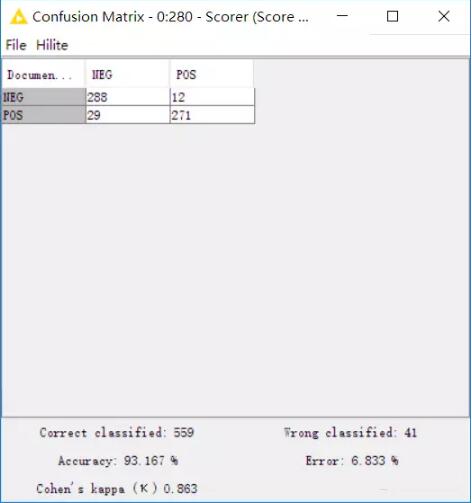
如此看来,我们的模型可以用来进行类似的文本情感分析。比如说网购的商品评论,企业官微下的评论等类似的情况,都可以用来进行情感分析。
如何能够让机器“读懂”人的情感?情感分析提供了解决的一个思路。这也使得它成为自然语言分析(Natural Language Processing)中最令人神往的山对面的“风景”。
什么是情感分类(sentiment classification)
简单说,就是对于一句或一段话,判断说话者的情感,是正向(积极)的,还是负向(消极)的。这种情感分类任务可以看作一个二分类问题。
完成情感分类的核心问题
决定分类准确率的关键在于特征的选取与语料的质量。其中特征问题解决的是:用什么样的特征来抽取,得到的文本才足够原始呢?每个词看似已经是文本的足够底层的特征,但其实也是经过高度抽象的。这也会给深度学习在自然语言领域的应用带来一些困难。同样,这也是提高模型准确度的一个有效的方法。
在上一篇情感分析的讲解中,我们已经知道如何使用KNIME构造一个情感分析模型。这一篇中,我们将使用N元语法(N-gram),借助KNIME来探究如何选取词语特征,获得的模型能够实现更准确地分类。
N元语法
在计算语言学中,n-gram指的是文本中连续的n个item。n-gram中如果n=1则为unigram,n=2则为bigram,n=3则为trigram。n>4后,则直接用数字指称,如4-gram,5gram。(Wikipedia)
以 I would like to go to Beijing. 这句话为例。
bigram为:
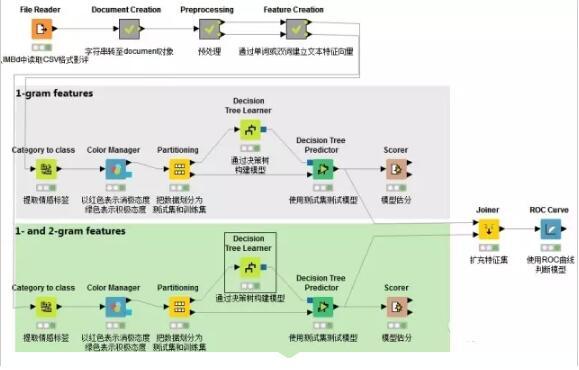
结点概览
1.读取CSV格式文件
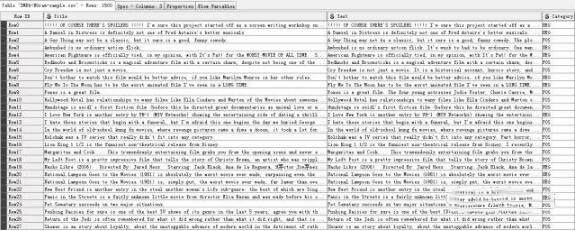
使用CSV reader结点读取一个CSV格式文件,该文件写入了1500条载于IMBD上的影评,并且给出了情感向量即POS(positive)和NEG(negative)。
2.字符串转化为文档格式
接下来将字符串转化为文档格式,继而使用“过滤”节点删除无关列,使文件只留下储存文档对象的一列。
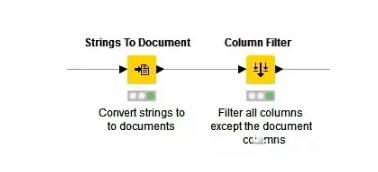
以上结点内属于Document creation元结点
3.数据预处理
首先计算特征词语需要在文档中出现最小次数N。利用java语句计算:out_MinDF = (Number_Rows / 100) * Min_Percentage
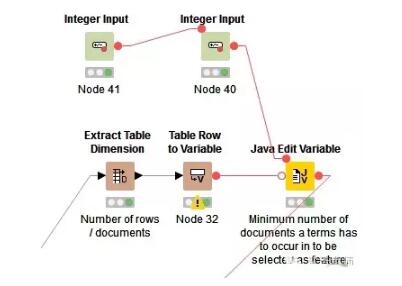
继而进行删除标点,删除数字,删除文档中出现次数小于N的词汇,将大写转化为小写,提取词语主干(stemmed)和删除停用词(stop word)。至此我们可以完成预处理。但是由于我们想探索的是双词分类与单词分类的效果差异,所以这里花开两朵各表一枝,双词分类的这一支不需要做主干提取和停用词删除的工作。
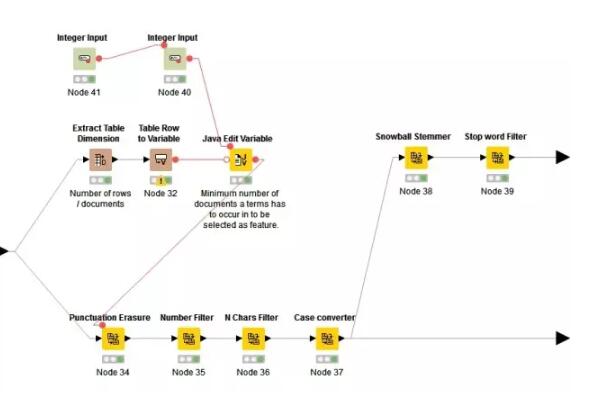
(stemmed意指将词的变形归类,使得机器在处理文本时减少需要跟踪的独特词汇,这会加快“标签化”处理的过程。停用词是人类语言中没有实际意义或功用的词语,如助词,限定词等)
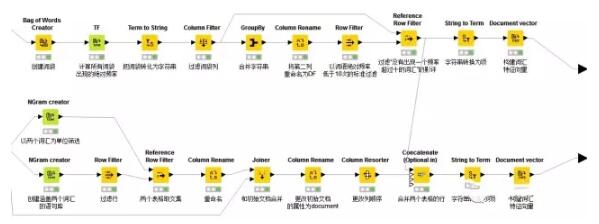
4.通过单词或双词建立文本特征向量
想象在一个巨大的文档集合,里面一共有M个文档,而文档里面的所有单词提取出来后,一起构成一个包含N个单词的词典,利用词袋(Bag-of-words)模型,每个文档都可以被表示成为一个N维向量(将每篇文档表示为一个向量,每一维度代表一个词语,其数值代表词语在该文档中的出现次数)。这样,就可以利用计算机来完成海量文档的分类过程。
一般来说,太多的特征会降低分类的准确度,所以需要使用一定的方法,来“选择”出信息量最丰富的特征,再使用这些特征来分类。
特征选择遵循如下步骤:
5.构建模型
通过决策树算法构建模型在上一篇已经讲过,需要注意的是本篇需要对1-gram特征和1-gram 2-gram集合特征分别构建模型,以进行比较。这里不再赘述。
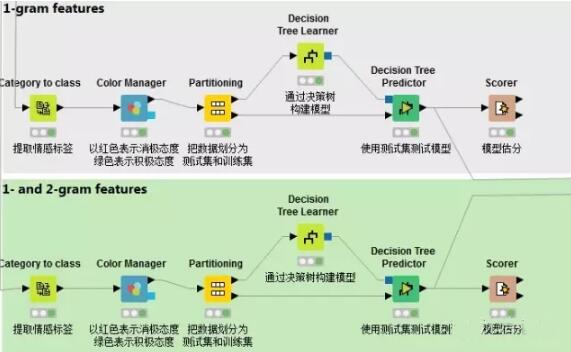
6.ROC曲线对比
在文档向量集创建后,词汇的情感分类已经被提取出来,系统自动创建了两种预测模型并打分。一个模型基于一个单独词汇的特征建立,第二个模型基于1-gram和2gram集合的特征。接着通过ROC接收器操作特性曲线(receiver operating characteristic curve)对这两个进行比较。
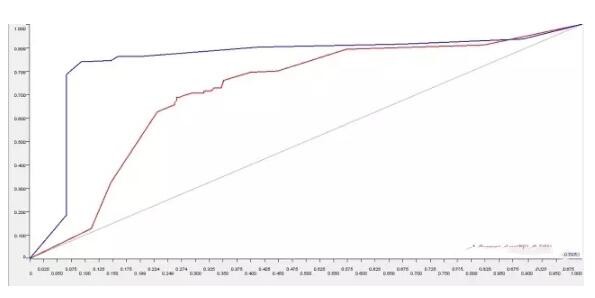
可以看出,在分析影评这一文本的情感态度时,使用N元语法构建出来的情感分类模型,诊断准确度更高,为85.05%。这样有助于我们针对“何种情感分类模型对NLP分析更为有效”这一问题时做出决策。
| 欢迎光临 开发者俱乐部 (http://xodn.com/) | Powered by Discuz! X3.2 |